Extracting Text Tags from Product Descriptions using Machine Learning

In the summer of 2019 I decided to enter the yearly company hackathon with a project that had been brewing in the back of my mind for months.
As part of its vast offerings in the travel space, TripAdvisor sells experiences, such as tours, tickets and other things to do all over the world. These tours are already organized based on an existing taxonomy but I felt that taxonomy was too rigid and inflexible to allow for more interesting applications.
Tags on the other hand allow far more flexibility and creativity:
- Tags suggest specific topics or themes without imposing a rigid hierarchy
- Tags make searching/filtering a lot easier and more organic
- Tags can be used to build machine learning models for product recommendation, product discovery, automatic curation of products, etc.
Apps like Pocket and Instapaper use text tags to give you suggestions and interesting ways of finding articles in your library.

Amazon uses text tags to categorize and filter their vast number of reviews

The first step to any of these applications is figuring out how to automatically extract these tags from the product description in an automated way so it can easily scale to hundreds of thousands of products.
Lucky for us, this is a simple application of NLP.
What's NLP?
In machine learning, any process that works with text fits under the umbrella of NLP (Natural Language Processing) Wikipedia defines NLP as
a subfield of AI concerned with the interactions between computers and human (natural) languages, in particular how to program computers to process and analyze large amounts of natural language data.”
Its applications are vast, from voice recognition, machine translation, sentiment analysis to chatbots and automated voice response systems.
What we're going to do however is actually pretty simple. Given the text description of a product, break down the text into individual tokens, (i.e. words) count how often they occur in the description, sort them by frequency and grab the top 10 words for each product.
The Method
Warning: The following section is pretty technical. Feel free to skim it so you at least get the gist of it
Before doing any work with text, we need to load it into our tool and preprocess it. Text can be very messy and that doesn't work well with machine learning algorithms. My favorite tool for doing any sort of machine learning or data science is Knime. It’s a free, visual workflow based analytics tool that has a wide variety of machine learning algorithms built-in, or available via extensions.
Here’s what the overall workflow looks like.

First we get all the product descriptions from the database and combine all the different text fields, like product name, overview and product description into a single column, convert them to documents (a native data structure Knime uses to work with text) and then apply standard NLP preprocessing steps. Next we calculate the frequency score, choose the top 10 tags based on this frequency score and output the result.
On the final step we group all the tags by product code into a comma separated list ready for deployment. We can also deliver the results into a table which then can be used further.
Here’s what the final result looks like

Pretty interesting right?
Ok let's dive a little deeper and see what's really happening. Here's a detailed look at the NLP preprocessing steps:

Since text in general tends to be pretty messy, we want to clean it up as much as possible by making all the words lowercase and removing all extraneous characters, like HTML tags, punctuation, numbers and any other weird characters like spaces, tabs, etc. This will drastically improve our results.

Continuing the preprocessing further we remove all the words with 3 or fewer letters like I, and, in, on, me, etc. These words are very frequent and they don't make for good tags.
Next we remove what are known as "stop words." These are also words we don't want to count as tags which appear frequently on the description, like for example tour, guide, lunch, dinner, drive, etc. This is a custom list that can be modified as needed.
Next we lemmatize all the words. This means we turn any plural nouns into their singular form; we take different forms of a word, such as organize, organizes, and organizing and make them all the same word organize.
We're finally done with preprocessing so now we can do the most important step, which is to calculate the term frequency score which we'll use for choosing our top 10 terms.

This score is known as TF-IDF which stands for term frequency, inverse document frequency. It's basically a count of how many times a word appears in a single product description multiplied by the inverse of how many times it appears across all the product descriptions in our list.
It strikes the right balance between the most frequent but not important terms and the less frequent but very important ones. It’s used extensively in NLP applications. The row filter further removes words that appear in fewer than 5% and more than 50% of the documents, to further limit our list of tags. These parameters are adjustable.

Next we generate a rank by sorting the keywords in descending order by the TF-IDF score so that the rank 1 has the highest TF-IDF score word for each product and we select the top 10
Alternative Approaches
Using the TF-IDF score is not the only method for generating keywords. Knime also has a couple of other algorithms (nodes) you can try, the Keygraph Keyword Extractor and the Chi Square Keyword Extractor. Both of these return similar results but they're not as adjustable as the TF-IDF method or as easy to explain.
Unexpected Results
Here's the mockup I used in my presentation with the tags generated from the workflow above then manually hard-coded into the static HTML of the product description page. As you can see the tags are not too bad. Ideally the tags will come from the database and be made clickable so you can easily find more related products and navigate the site more organically, but this was a two-day hackathon and the proof of concept was sufficient.
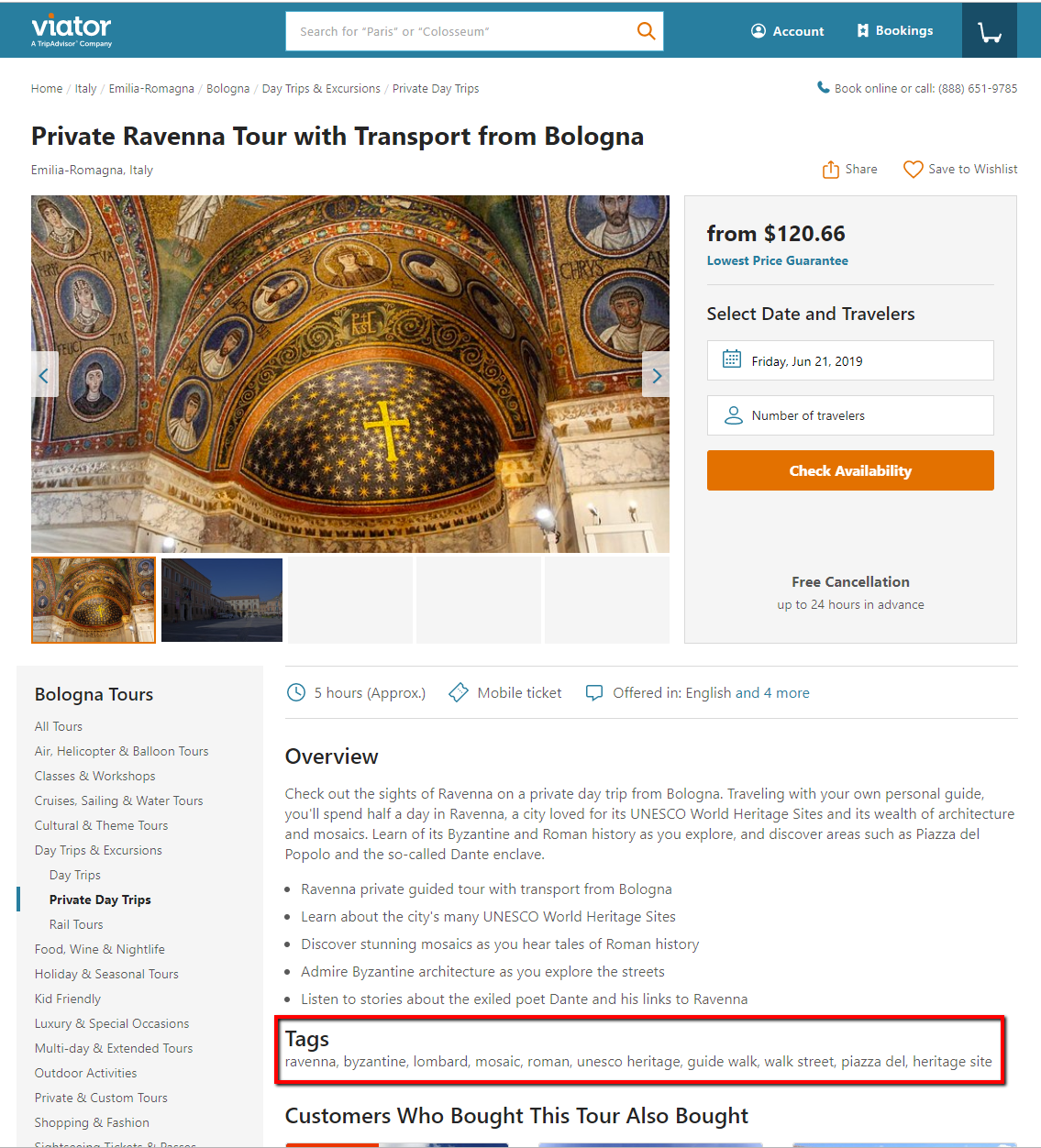
What I didn’t expect however was the interest that it drew. After the first round of presentations, I was surprised to make it to the second round, where I presented in front of a panel of judges made up of senior executives and a large group of my peers.
Though I didn’t get to the finals, I found out that there was an effort already underway to revamp the existing taxonomy and I got involved with it. This helped me grow my professional network beyond what I would have otherwise.
A few weeks later on I was also involved in a collaboration with MIT MBAn students who worked on a similar project under my leadership. I can proudly say this was amongst the most interesting projects I saw presented there. I’ll write about that story another time.